


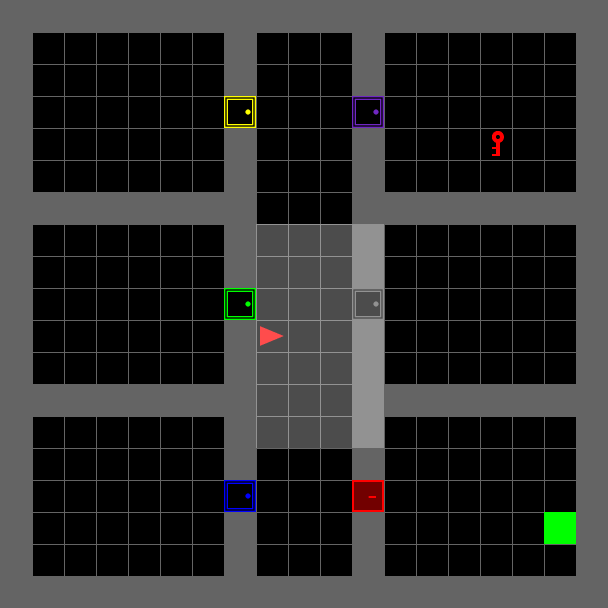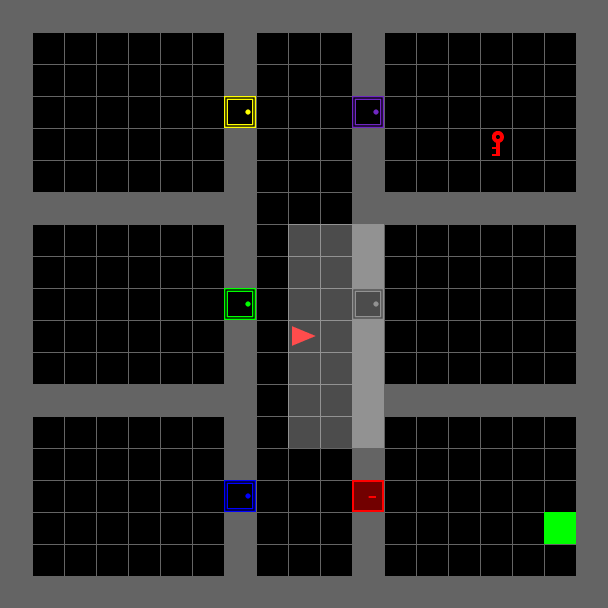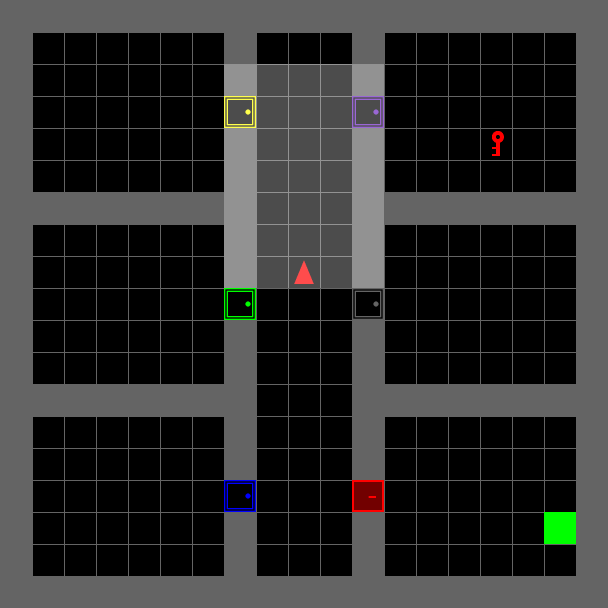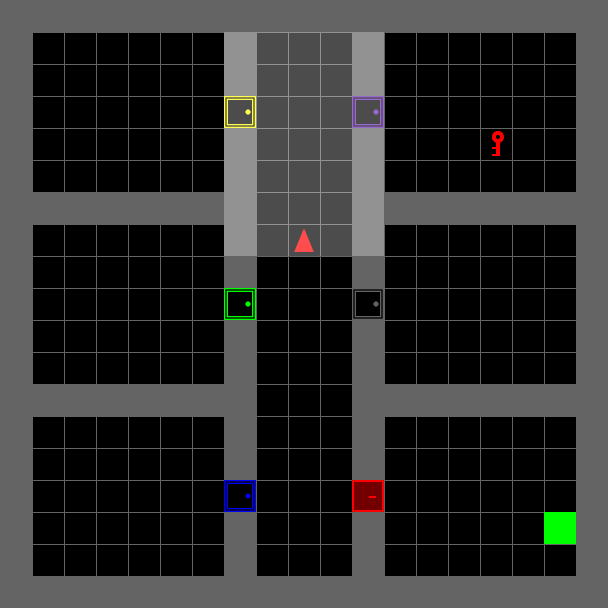
Locked Room#
Action Space |
|
Observation Space |
|
Reward Range |
|
Creation |
|
Description#
The environment has six rooms, one of which is locked. The agent receives a textual mission string as input, telling it which room to go to in order to get the key that opens the locked room. It then has to go into the locked room in order to reach the final goal. This environment is extremely difficult to solve with vanilla reinforcement learning alone.
Mission Space#
“get the {lockedroom_color} key from the {keyroom_color} room, unlock the {door_color} door and go to the goal”
{lockedroom_color}, {keyroom_color}, and {door_color} can be “red”, “green”, “blue”, “purple”, “yellow” or “grey”.
Action Space#
Num |
Name |
Action |
|---|---|---|
0 |
left |
Turn left |
1 |
right |
Turn right |
2 |
forward |
Move forward |
3 |
pickup |
Pick up an object |
4 |
drop |
Unused |
5 |
toggle |
Toggle/activate an object |
6 |
done |
Unused |
Observation Encoding#
Each tile is encoded as a 3 dimensional tuple:
(OBJECT_IDX, COLOR_IDX, STATE)OBJECT_TO_IDXandCOLOR_TO_IDXmapping can be found in minigrid/core/constants.pySTATErefers to the door state with 0=open, 1=closed and 2=locked
Rewards#
A reward of ‘1 - 0.9 * (step_count / max_steps)’ is given for success, and ‘0’ for failure.
Termination#
The episode ends if any one of the following conditions is met:
The agent reaches the goal.
Timeout (see
max_steps).
Registered Configurations#
MiniGrid-LockedRoom-v0